世界のAIトレーニングデータセット市場(2025年~2033年):ゲームタイプ別、その他

※本ページに記載されている内容は英文レポートの概要と目次を日本語に自動翻訳したものです。英文レポートの情報と購入方法はお問い合わせください。
*** 本調査レポートに関するお問い合わせ ***
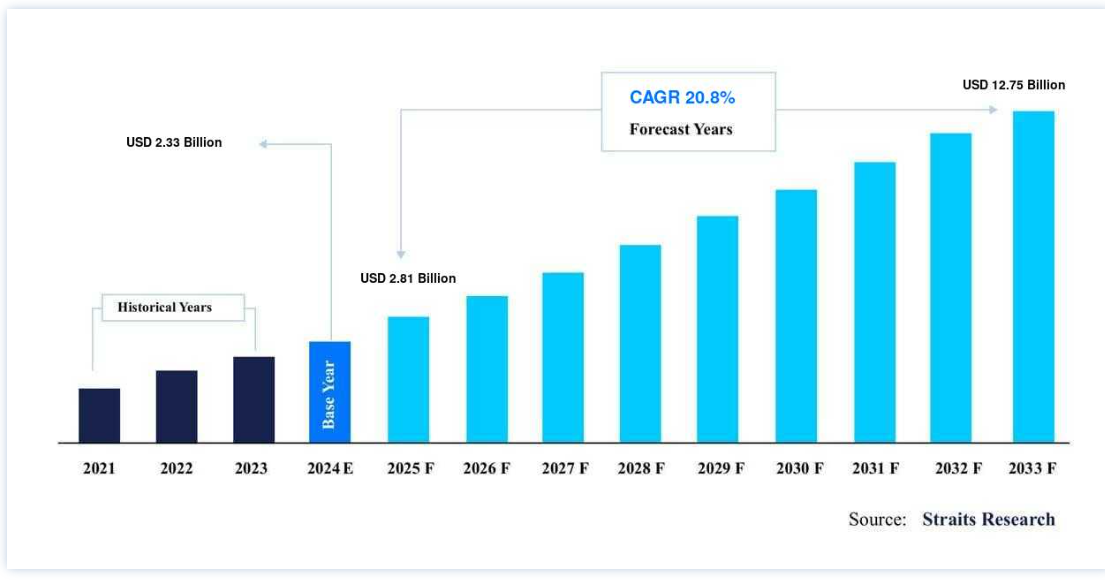
世界のAIトレーニングデータセット市場規模は、2024年には23億3000万米ドルと評価され、2025年には28億1000万米ドル、2033年には127億5000万米ドルに達すると予測されている。予測期間(2025年~2033年)中のCAGRは20.8%で成長する。
人工知能は、機械に失敗から学び、人間の行動を模倣し、環境に適応する能力を与える。 これらの機械は、膨大な量のデータを分析し、特定の活動を実行するためのパターンを見つけるように教えられている。 これらのロボットに特定のタスクを実行させるには、特殊なデータセットが必要となる。 人工知能のトレーニング用データセットのニーズは、この需要の高まりに応えるために高まっている。 提供されるデータセットは、機械がどの程度完全に動作するかを決定し、AIの有効性を向上させる。 その結果、一流のトレーニングデータセットを提供することが重要になる。 さらに、データ準備のスピードアップや予測精度の向上にも役立つ。 その結果、市場プレーヤーはデータ品質の向上を支援する企業の買収に注力している。
AIトレーニングデータセット市場の成長要因
AIと機械学習の急成長
ビッグデータの出現は、膨大な量のデータの記録、保存、分析を必要とするため、人工知能市場の拡大に拍車をかけると予想される。 エンドユーザーは、ビッグデータに関連する計算モデルの監視と強化の必要性をより重視している。 この焦点により、人工知能ソリューションの採用が加速している。 アノテーションされたデータは、音声認識や画像識別のような重要な領域でAIモデルや機械学習システムを訓練する触媒となるため、人工知能の採用によりAI訓練データセットの需要が大幅に増加すると予測されている。
データアノテーションは、将来の結果を予測し、意思決定を行うために不可欠なデータを明示的に供給することで、AIを強化する。 国家情報、詐欺検出、マーケティング、医療情報学、サイバーセキュリティなど、多くのアプリケーションからのデータを含むドメイン固有のデータは、多くの公的機関や民間組織によって収集されています。 各データの精度を継続的に向上させることで、データ注釈はこのような構造化されていない教師なしデータのラベリングを可能にします。
抑制要因
発展途上地域における技術導入の遅れ
アジア太平洋地域では、データ収集は個人情報保護に関する実質的な制限によって制約されると予想される。
例えば、日本では個人情報保護法が施行され、機密性の高い個人データを承認されていない団体や場所に送信することが禁止されている。
データの不正確な分類は、市場拡大の障壁となっている。
データアノテーションツールの主な課題は、出力精度である。 データの不正確さなど、出力の品質に関する懸念は最小限に抑えるべきである。 状況によっては、手作業によるラベル付けが正しく行われず、これらのラベルを見つけるのに時間がかかり、ビジネスの経費が増加することもある。 しかし、高度なアルゴリズムの開発により、自動AIデータトレーニングデータセットツールの精度が向上し、手動アノテーションの必要性とツールコストが低下すると予想される。
市場機会
多様化する産業分野でのトレーニングデータセットの用途拡大
デジタルキャプチャデバイス、特にスマートフォンに内蔵されたカメラによって、写真やビデオの形のデジタルコンテンツの量は飛躍的に増加している。 数多くのアプリケーション、ウェブサイト、ソーシャルネットワーク、その他のデジタルチャネルを通じて、膨大な量の視覚情報やデジタル情報が収集され、共有されている。 データアノテーションにより、いくつかの企業はこの自由にアクセスできるウェブコンテンツを利用して、顧客により革新的でより良いサービスを提供している。 電子カルテ(EHR)システムの使用増加により収集された非構造化テキスト記録は、現在、臨床研究にとって最も重要なリソースの1つとなっています。 これらの要因は、予測期間中に市場成長のための途方もない機会を生み出すと予測されています。
地域別インサイト
アジア太平洋地域: 市場シェア21.5%で圧倒的な地域
アジア太平洋地域は、世界のAIトレーニングデータセット市場で最も重要な株主であり、予測期間中に21.5%のCAGRで成長すると予想されている。 インドのような発展途上国の組織は、企業を近代化するために革新的な技術の採用率を大幅に高めている。 さらに、いくつかの大手企業はアジア太平洋地域における影響力の拡大に注力している。
例えば、マイクロソフトは、地磁気や屋内Wi-Fiシグネチャーなど、中国の都市の建物から様々なデータを収集するために、インドア・ロケーション・データセットというデータセットを作成した。
これらのデータセットは、ローカライゼーション、屋内環境、ナビゲーションの研究と発展に役立っている。 加えて、マイクロソフトや他の重要なプレーヤーは、この宗教での存在感を高めている。 これらの要素は、この地域でのデータセット利用を増加させ、予測期間を通じて著しく成長すると予測されている。
ヨーロッパ CAGRが最も高い急成長地域
欧州はCAGR 20.6%で成長し、予測期間中に1,990.20百万米ドルを生み出すと予想されている。 ワークフロー管理、ブランド購買広告、トレンド予測などの技術を統合することで、AIは欧州における企業経営の実践を進化させてきた。 これらの要因により、企業は機械学習と人工知能技術に多額の投資を行い、AIトレーニングデータセット市場の拡大に拍車をかけている。 企業の生産性を向上させるため、多数のハイテク企業や小規模新興企業も人工知能の導入に投資している。 AIトレーニング用データセット市場の成長は、トレーニング用データセットに対する需要の高まりと人工知能のニーズとの直接的な関係によって加速している。
北米は予測期間中に大きく成長すると予測されている。 ベンダー各社は、北米の新興分野における人工知能技術の採用を急ぐため、新しいデータセットの供給に注力している。
例えば、グーグルLLCのウェイモLLCは、無人運転車用の新しいデータセットを発表した。 このデータセットには、歩行者、自転車、その他の物体の存在を含む様々な運転状況下で、ビデオセンサーやLiDARを介して収集されたセンサーデータが含まれている。
このような進歩は、トレーニングデータセットの市場受容に影響を与え、トレーニングデータセット市場のかなりの部分を占めている。
ラテンアメリカの金融機関は、国際的な金融機関と同様に、AIなどの新技術を頻繁に導入しているが、いくつかの特別な困難にも直面している。 幸いなことに、こうした障害を克服するのは簡単になってきている。 ラテンアメリカ諸国は、北米諸国と比較して技術や投資の水準が低いにもかかわらず、優れた資源を活用して機会を活用し、問題に取り組むことを決断するかもしれない。 この地域の国々は、急速な技術開発を認識し、将来性を利用するための国家戦略を立てるべきである。
AIトレーニングデータセット市場のセグメンテーション分析
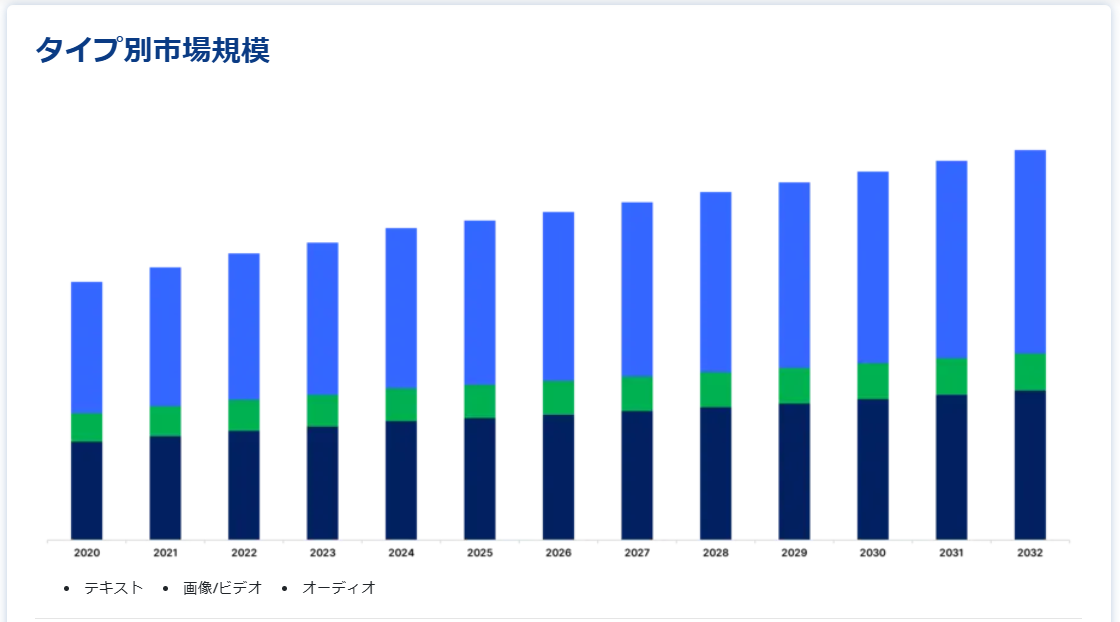
タイプ別
画像/動画分野は、市場貢献度が最も高く、予測期間中の年平均成長率は22.2%と予想されている。 これは、画像/ビデオにキャプションやキーワード、またはコンピュータシステムで手動でメタデータを付与するプロセスである。 このような大規模な拡大は、より幅広い文脈で利用できる新しいデータセットを提供しようとする主要な関係者の努力によるものである。
例えば、世界的なテクノロジービジネスを展開するGoogle LLCは最近、数百万枚の写真と数千のランドマークを含む新しいAIトレーニングデータセット、Google-Locations-v2を発表した。
テキスト・セグメントは、臨床研究や電子商取引における応用の高まりにより、大きなシェアを占めている。 電子カルテ(EHR)システムの導入が進むにつれ、非構造化テキスト文書を含む臨床データの蓄積は、臨床研究の貴重なリソースの1つとなっている。 統計的自然言語処理(NLP)モデルは、臨床テキストに埋め込まれた情報を解き明かすために開発されてきた。 テキストデータセット、またはテキストに類似したデータを多数のソースから収集することは、人間の言語のテキスト表現を理解できる技術の開発に役立ちます。 機械やアプリケーションがここまで進歩するためには、膨大な量のテキストデータを消費しなければならない。 テキスト・ラベリングは、ソーシャルメディア・モニタリングにおいて、推薦システムを構築するために大いに利用されている。
例えば、eコマース企業はソーシャルメディアデータを利用して、顧客の購買意欲に影響を与えている。
産業分野別
自動車分野が最も高い市場シェアを占め、予測期間中のCAGRは21.1%で成長すると予測されている。 自動車産業には、自動車製造やサプライチェーン事業、自律走行車の開発などが含まれる。 自動車産業におけるデータ収集とラベリングの主なユースケースは、車内エンターテインメント用の音声認識と音声認識、ユーザー行動の理解と予測、自律走行車である。 AIは、自律走行車から製造現場での最先端のロボット工学に至るまで、自動車産業がこれまでどのように運営されてきたかを急速に変えつつある。 人工知能は、機械学習の画期的な可能性のおかげで、自動車部門に新たな価値の未来をもたらす先導役となっている。 自律走行車におけるAIの活用は広く認知され、称賛されているが、その他の業界の優先分野には、生産、エンジニアリング、サプライチェーン、カスタマー・エクスペリエンス、モビリティ・サービスなどがある。
IT分野は予測期間中に大きく成長すると予想されている。 この分野には、テクノロジー、ソフトウェア、関連サービス事業が含まれる。 IT業界におけるデータ収集とラベリングの主なユースケースは、人間の言葉をより理解するための自動音声認識、顧客関係管理(CRM)/顧客経験管理(CEM)、コンサルティングサービス、機械翻訳、ソーシャルメディア分析、バーチャルアシスタント、チャットボットなどである。 市場では、さまざまなテクノロジー企業が機械学習技術を利用して、ユーザー体験を向上させ、革新的な製品を開発している。 機械学習技術を効率化するには、MLアルゴリズムを継続的に最適化するための高品質な学習データが必要である。 その上、高品質のデータセットは、IT企業がコンピュータ・ビジョン、クラウドソーシング、データ分析、バーチャル・アシスタントなどの様々なソリューションを強化するのに役立つ。 このような要因が、同分野におけるトレーニングデータセットの利用率の高さにつながっている。
ガートナーによると、2023年までに、総合的なエクスペリエンス戦略を持たない政府の85%以上がサービスの変革に失敗するため、政府はデジタル・イニシアチブの拡大に集中すべきである。 その結果、政府は企業に倣ってAIへの投資を準備している。
例えば、中国のインターネット企業Terminusとデンマークのデザイン会社BIGは最近、中国南西部の重慶市に「AIシティ」であるCloud Valleyを開発する計画を発表した。
データ収集・ラベリング市場では、予測期間中、小売分野も大きく成長すると予想されている。 小売・eコマース分野では、食料品店、eコマースプラットフォーム、小売チェーン/コンビニエンスストアのデータ収集とラベリングプロセスが行われている。 画像ラベリングの助けを借りて、オンラインの買い物客は、好みの質感、プリント、または色の写真を撮ることで、衣類やアクセサリーを検索することができる。 スマートフォンで撮影した写真はアプリにアップロードされ、AI技術を使って商品の在庫を検索し、類似商品を見つける。
AIトレーニングデータセット市場のセグメンテーション
タイプ別(2021年~2033年)
テキスト
画像/動画
音声
産業分野別(2021年~2033年)
IT
自動車
政府
ヘルスケア
金融
小売およびEコマース
その他
目次
1. エグゼクティブサマリー
2. 調査範囲とセグメンテーション
3. 市場機会の評価
4. 市場動向
5. 市場の評価
6. 規制の枠組み
7. ESGの動向
8. 世界のAIトレーニングデータセット市場規模分析
9. 北米のAIトレーニングデータセット市場分析
10. ヨーロッパのAIトレーニングデータセット市場分析
11. APACのAIトレーニングデータセット市場分析
12. 中東・アフリカのAIトレーニングデータセット市場分析
13. ラタムのAIトレーニングデータセット市場分析
14. 競合情勢
15. 市場プレイヤーの評価
16. 調査方法
17. 付録
18. 免責事項
*** 本調査レポートに関するお問い合わせ ***
